 +
+## Welcome to Firecrawl
+
+[Firecrawl](https://firecrawl.dev?ref=github) is an API service that takes a URL, crawls it, and converts it into clean markdown. We crawl all accessible subpages and give you clean markdown for each. No sitemap required.
+
+## How to use it?
+
+We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
+
+Check out the following resources to get started:
+
+* [x] **API**: [Documentation](https://docs.firecrawl.dev/api-reference/introduction)
+* [x] **SDKs**: [Python](https://docs.firecrawl.dev/sdks/python), [Node](https://docs.firecrawl.dev/sdks/node)
+* [x] **LLM Frameworks**: [Langchain (python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/), [Langchain (js)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl), [Llama Index](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader), [Crew.ai](https://docs.crewai.com/), [Composio](https://composio.dev/tools/firecrawl/all), [PraisonAI](https://docs.praison.ai/firecrawl/), [Superinterface](https://superinterface.ai/docs/assistants/functions/firecrawl), [Vectorize](https://docs.vectorize.io/integrations/source-connectors/firecrawl)
+* [x] **Low-code Frameworks**: [Dify](https://dify.ai/blog/dify-ai-blog-integrated-with-firecrawl), [Langflow](https://docs.langflow.org/), [Flowise AI](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl), [Cargo](https://docs.getcargo.io/integration/firecrawl), [Pipedream](https://pipedream.com/apps/firecrawl/)
+* [x] **Community SDKs**: [Go](https://docs.firecrawl.dev/sdks/go), [Rust](https://docs.firecrawl.dev/sdks/rust) (v1)
+* [x] **Others**: [Zapier](https://zapier.com/apps/firecrawl/integrations), [Pabbly Connect](https://www.pabbly.com/connect/integrations/firecrawl/)
+* [ ] Want an SDK or Integration? Let us know by opening an issue.
+
+**Self-host:** To self-host refer to guide [here](/contributing/self-host).
+
+### API Key
+
+To use the API, you need to sign up on [Firecrawl](https://firecrawl.dev) and get an API key.
+
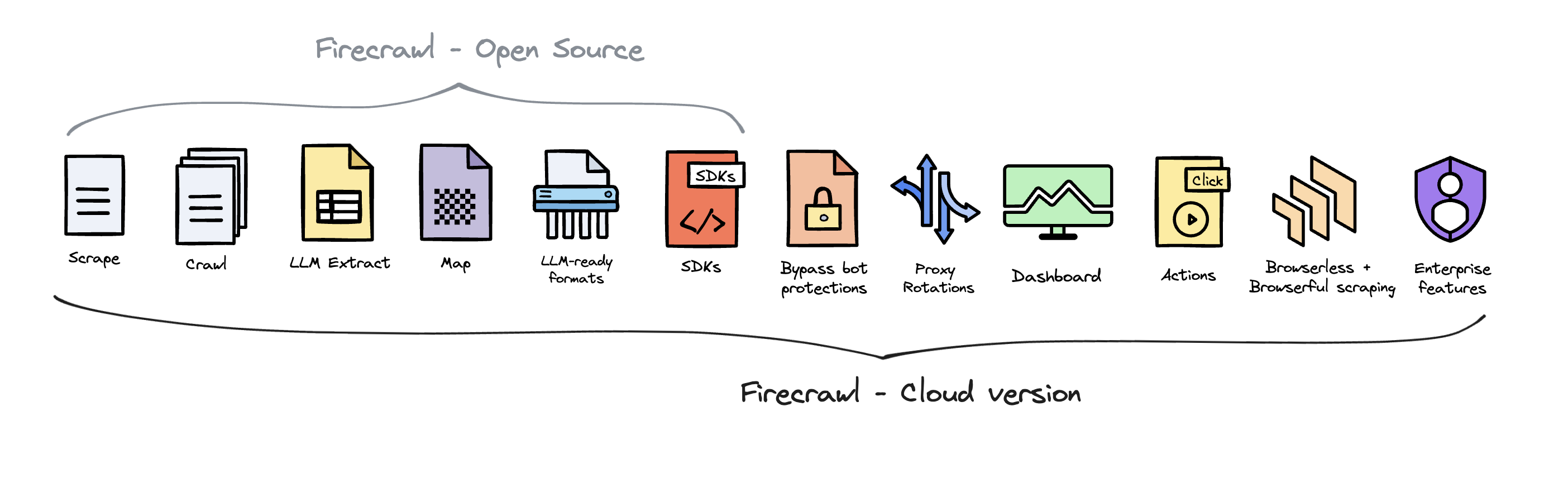
+### Features
+
+* [**Scrape**](#scraping): scrapes a URL and get its content in LLM-ready format (markdown, summary, structured data via [json mode](#json-mode), screenshot, html)
+* [**Crawl**](#crawling): scrapes all the URLs of a web page and return content in LLM-ready format
+* [**Map**](/features/map): input a website and get all the website urls - extremely fast
+* [**Search**](/features/search): search the web and get full content from results
+* [**Extract**](/features/extract): get structured data from single page, multiple pages or entire websites with AI.
+
+### Powerful Capabilities
+
+* **LLM-ready formats**: markdown, summary, structured data, screenshot, HTML, links, metadata
+* **The hard stuff**: proxies, anti-bot mechanisms, dynamic content (js-rendered), output parsing, orchestration
+* **Lightning fast**: Get results in seconds—built for speed and high-throughput use cases.
+* **Customizability**: exclude tags, crawl behind auth walls with custom headers, max crawl depth, etc...
+* **Media parsing**: pdfs, docx, images.
+* **Reliability first**: designed to get the data you need - no matter how hard it is.
+* **Actions**: click, scroll, input, wait and more before extracting data
+
+You can find all of Firecrawl's capabilities and how to use them in our [documentation](https://docs.firecrawl.dev/api-reference/v2-introduction)
+
+## Installing Firecrawl
+
+
+
+## Welcome to Firecrawl
+
+[Firecrawl](https://firecrawl.dev?ref=github) is an API service that takes a URL, crawls it, and converts it into clean markdown. We crawl all accessible subpages and give you clean markdown for each. No sitemap required.
+
+## How to use it?
+
+We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
+
+Check out the following resources to get started:
+
+* [x] **API**: [Documentation](https://docs.firecrawl.dev/api-reference/introduction)
+* [x] **SDKs**: [Python](https://docs.firecrawl.dev/sdks/python), [Node](https://docs.firecrawl.dev/sdks/node)
+* [x] **LLM Frameworks**: [Langchain (python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/), [Langchain (js)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl), [Llama Index](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader), [Crew.ai](https://docs.crewai.com/), [Composio](https://composio.dev/tools/firecrawl/all), [PraisonAI](https://docs.praison.ai/firecrawl/), [Superinterface](https://superinterface.ai/docs/assistants/functions/firecrawl), [Vectorize](https://docs.vectorize.io/integrations/source-connectors/firecrawl)
+* [x] **Low-code Frameworks**: [Dify](https://dify.ai/blog/dify-ai-blog-integrated-with-firecrawl), [Langflow](https://docs.langflow.org/), [Flowise AI](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl), [Cargo](https://docs.getcargo.io/integration/firecrawl), [Pipedream](https://pipedream.com/apps/firecrawl/)
+* [x] **Community SDKs**: [Go](https://docs.firecrawl.dev/sdks/go), [Rust](https://docs.firecrawl.dev/sdks/rust) (v1)
+* [x] **Others**: [Zapier](https://zapier.com/apps/firecrawl/integrations), [Pabbly Connect](https://www.pabbly.com/connect/integrations/firecrawl/)
+* [ ] Want an SDK or Integration? Let us know by opening an issue.
+
+**Self-host:** To self-host refer to guide [here](/contributing/self-host).
+
+### API Key
+
+To use the API, you need to sign up on [Firecrawl](https://firecrawl.dev) and get an API key.
+
+### Features
+
+* [**Scrape**](#scraping): scrapes a URL and get its content in LLM-ready format (markdown, summary, structured data via [json mode](#json-mode), screenshot, html)
+* [**Crawl**](#crawling): scrapes all the URLs of a web page and return content in LLM-ready format
+* [**Map**](/features/map): input a website and get all the website urls - extremely fast
+* [**Search**](/features/search): search the web and get full content from results
+* [**Extract**](/features/extract): get structured data from single page, multiple pages or entire websites with AI.
+
+### Powerful Capabilities
+
+* **LLM-ready formats**: markdown, summary, structured data, screenshot, HTML, links, metadata
+* **The hard stuff**: proxies, anti-bot mechanisms, dynamic content (js-rendered), output parsing, orchestration
+* **Lightning fast**: Get results in seconds—built for speed and high-throughput use cases.
+* **Customizability**: exclude tags, crawl behind auth walls with custom headers, max crawl depth, etc...
+* **Media parsing**: pdfs, docx, images.
+* **Reliability first**: designed to get the data you need - no matter how hard it is.
+* **Actions**: click, scroll, input, wait and more before extracting data
+
+You can find all of Firecrawl's capabilities and how to use them in our [documentation](https://docs.firecrawl.dev/api-reference/v2-introduction)
+
+## Installing Firecrawl
+
+ +
+## Contributing
+
+We love contributions! Please read our [contributing guide](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md) before submitting a pull request.
diff --git a/package-lock.json b/package-lock.json
index 623af58..1840cc3 100644
--- a/package-lock.json
+++ b/package-lock.json
@@ -8,6 +8,7 @@
"name": "ai-podcast",
"version": "0.1.0",
"dependencies": {
+ "@mendable/firecrawl-js": "^4.3.5",
"@radix-ui/react-progress": "^1.1.7",
"@radix-ui/react-slot": "^1.2.3",
"class-variance-authority": "^0.7.1",
@@ -761,6 +762,21 @@
"@jridgewell/sourcemap-codec": "^1.4.14"
}
},
+ "node_modules/@mendable/firecrawl-js": {
+ "version": "4.3.5",
+ "resolved": "https://registry.npmjs.org/@mendable/firecrawl-js/-/firecrawl-js-4.3.5.tgz",
+ "integrity": "sha512-6Vd0bEVD0hOS4SXlmrBnOkm86WWqEITHSTXwdnjm6SkTz6ZF6o85gGHUvOYoky4w7AoLctAv8yqrm6aZsy4lfQ==",
+ "license": "MIT",
+ "dependencies": {
+ "axios": "^1.12.2",
+ "typescript-event-target": "^1.1.1",
+ "zod": "^3.23.8",
+ "zod-to-json-schema": "^3.23.0"
+ },
+ "engines": {
+ "node": ">=22.0.0"
+ }
+ },
"node_modules/@napi-rs/wasm-runtime": {
"version": "0.2.12",
"resolved": "https://registry.npmjs.org/@napi-rs/wasm-runtime/-/wasm-runtime-0.2.12.tgz",
@@ -2229,6 +2245,12 @@
"node": ">= 0.4"
}
},
+ "node_modules/asynckit": {
+ "version": "0.4.0",
+ "resolved": "https://registry.npmjs.org/asynckit/-/asynckit-0.4.0.tgz",
+ "integrity": "sha512-Oei9OH4tRh0YqU3GxhX79dM/mwVgvbZJaSNaRk+bshkj0S5cfHcgYakreBjrHwatXKbz+IoIdYLxrKim2MjW0Q==",
+ "license": "MIT"
+ },
"node_modules/available-typed-arrays": {
"version": "1.0.7",
"resolved": "https://registry.npmjs.org/available-typed-arrays/-/available-typed-arrays-1.0.7.tgz",
@@ -2255,6 +2277,17 @@
"node": ">=4"
}
},
+ "node_modules/axios": {
+ "version": "1.12.2",
+ "resolved": "https://registry.npmjs.org/axios/-/axios-1.12.2.tgz",
+ "integrity": "sha512-vMJzPewAlRyOgxV2dU0Cuz2O8zzzx9VYtbJOaBgXFeLc4IV/Eg50n4LowmehOOR61S8ZMpc2K5Sa7g6A4jfkUw==",
+ "license": "MIT",
+ "dependencies": {
+ "follow-redirects": "^1.15.6",
+ "form-data": "^4.0.4",
+ "proxy-from-env": "^1.1.0"
+ }
+ },
"node_modules/axobject-query": {
"version": "4.1.0",
"resolved": "https://registry.npmjs.org/axobject-query/-/axobject-query-4.1.0.tgz",
@@ -2319,7 +2352,6 @@
"version": "1.0.2",
"resolved": "https://registry.npmjs.org/call-bind-apply-helpers/-/call-bind-apply-helpers-1.0.2.tgz",
"integrity": "sha512-Sp1ablJ0ivDkSzjcaJdxEunN5/XvksFJ2sMBFfq6x0ryhQV/2b/KwFe21cMpmHtPOSij8K99/wSfoEuTObmuMQ==",
- "dev": true,
"license": "MIT",
"dependencies": {
"es-errors": "^1.3.0",
@@ -2450,6 +2482,18 @@
"dev": true,
"license": "MIT"
},
+ "node_modules/combined-stream": {
+ "version": "1.0.8",
+ "resolved": "https://registry.npmjs.org/combined-stream/-/combined-stream-1.0.8.tgz",
+ "integrity": "sha512-FQN4MRfuJeHf7cBbBMJFXhKSDq+2kAArBlmRBvcvFE5BB1HZKXtSFASDhdlz9zOYwxh8lDdnvmMOe/+5cdoEdg==",
+ "license": "MIT",
+ "dependencies": {
+ "delayed-stream": "~1.0.0"
+ },
+ "engines": {
+ "node": ">= 0.8"
+ }
+ },
"node_modules/concat-map": {
"version": "0.0.1",
"resolved": "https://registry.npmjs.org/concat-map/-/concat-map-0.0.1.tgz",
@@ -2601,6 +2645,15 @@
"url": "https://github.com/sponsors/ljharb"
}
},
+ "node_modules/delayed-stream": {
+ "version": "1.0.0",
+ "resolved": "https://registry.npmjs.org/delayed-stream/-/delayed-stream-1.0.0.tgz",
+ "integrity": "sha512-ZySD7Nf91aLB0RxL4KGrKHBXl7Eds1DAmEdcoVawXnLD7SDhpNgtuII2aAkg7a7QS41jxPSZ17p4VdGnMHk3MQ==",
+ "license": "MIT",
+ "engines": {
+ "node": ">=0.4.0"
+ }
+ },
"node_modules/detect-libc": {
"version": "2.1.0",
"resolved": "https://registry.npmjs.org/detect-libc/-/detect-libc-2.1.0.tgz",
@@ -2628,7 +2681,6 @@
"version": "1.0.1",
"resolved": "https://registry.npmjs.org/dunder-proto/-/dunder-proto-1.0.1.tgz",
"integrity": "sha512-KIN/nDJBQRcXw0MLVhZE9iQHmG68qAVIBg9CqmUYjmQIhgij9U5MFvrqkUL5FbtyyzZuOeOt0zdeRe4UY7ct+A==",
- "dev": true,
"license": "MIT",
"dependencies": {
"call-bind-apply-helpers": "^1.0.1",
@@ -2733,7 +2785,6 @@
"version": "1.0.1",
"resolved": "https://registry.npmjs.org/es-define-property/-/es-define-property-1.0.1.tgz",
"integrity": "sha512-e3nRfgfUZ4rNGL232gUgX06QNyyez04KdjFrF+LTRoOXmrOgFKDg4BCdsjW8EnT69eqdYGmRpJwiPVYNrCaW3g==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -2743,7 +2794,6 @@
"version": "1.3.0",
"resolved": "https://registry.npmjs.org/es-errors/-/es-errors-1.3.0.tgz",
"integrity": "sha512-Zf5H2Kxt2xjTvbJvP2ZWLEICxA6j+hAmMzIlypy4xcBg1vKVnx89Wy0GbS+kf5cwCVFFzdCFh2XSCFNULS6csw==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -2781,7 +2831,6 @@
"version": "1.1.1",
"resolved": "https://registry.npmjs.org/es-object-atoms/-/es-object-atoms-1.1.1.tgz",
"integrity": "sha512-FGgH2h8zKNim9ljj7dankFPcICIK9Cp5bm+c2gQSYePhpaG5+esrLODihIorn+Pe6FGJzWhXQotPv73jTaldXA==",
- "dev": true,
"license": "MIT",
"dependencies": {
"es-errors": "^1.3.0"
@@ -2794,7 +2843,6 @@
"version": "2.1.0",
"resolved": "https://registry.npmjs.org/es-set-tostringtag/-/es-set-tostringtag-2.1.0.tgz",
"integrity": "sha512-j6vWzfrGVfyXxge+O0x5sh6cvxAog0a/4Rdd2K36zCMV5eJ+/+tOAngRO8cODMNWbVRdVlmGZQL2YS3yR8bIUA==",
- "dev": true,
"license": "MIT",
"dependencies": {
"es-errors": "^1.3.0",
@@ -3401,6 +3449,26 @@
"dev": true,
"license": "ISC"
},
+ "node_modules/follow-redirects": {
+ "version": "1.15.11",
+ "resolved": "https://registry.npmjs.org/follow-redirects/-/follow-redirects-1.15.11.tgz",
+ "integrity": "sha512-deG2P0JfjrTxl50XGCDyfI97ZGVCxIpfKYmfyrQ54n5FO/0gfIES8C/Psl6kWVDolizcaaxZJnTS0QSMxvnsBQ==",
+ "funding": [
+ {
+ "type": "individual",
+ "url": "https://github.com/sponsors/RubenVerborgh"
+ }
+ ],
+ "license": "MIT",
+ "engines": {
+ "node": ">=4.0"
+ },
+ "peerDependenciesMeta": {
+ "debug": {
+ "optional": true
+ }
+ }
+ },
"node_modules/for-each": {
"version": "0.3.5",
"resolved": "https://registry.npmjs.org/for-each/-/for-each-0.3.5.tgz",
@@ -3417,11 +3485,26 @@
"url": "https://github.com/sponsors/ljharb"
}
},
+ "node_modules/form-data": {
+ "version": "4.0.4",
+ "resolved": "https://registry.npmjs.org/form-data/-/form-data-4.0.4.tgz",
+ "integrity": "sha512-KrGhL9Q4zjj0kiUt5OO4Mr/A/jlI2jDYs5eHBpYHPcBEVSiipAvn2Ko2HnPe20rmcuuvMHNdZFp+4IlGTMF0Ow==",
+ "license": "MIT",
+ "dependencies": {
+ "asynckit": "^0.4.0",
+ "combined-stream": "^1.0.8",
+ "es-set-tostringtag": "^2.1.0",
+ "hasown": "^2.0.2",
+ "mime-types": "^2.1.12"
+ },
+ "engines": {
+ "node": ">= 6"
+ }
+ },
"node_modules/function-bind": {
"version": "1.1.2",
"resolved": "https://registry.npmjs.org/function-bind/-/function-bind-1.1.2.tgz",
"integrity": "sha512-7XHNxH7qX9xG5mIwxkhumTox/MIRNcOgDrxWsMt2pAr23WHp6MrRlN7FBSFpCpr+oVO0F744iUgR82nJMfG2SA==",
- "dev": true,
"license": "MIT",
"funding": {
"url": "https://github.com/sponsors/ljharb"
@@ -3462,7 +3545,6 @@
"version": "1.3.0",
"resolved": "https://registry.npmjs.org/get-intrinsic/-/get-intrinsic-1.3.0.tgz",
"integrity": "sha512-9fSjSaos/fRIVIp+xSJlE6lfwhES7LNtKaCBIamHsjr2na1BiABJPo0mOjjz8GJDURarmCPGqaiVg5mfjb98CQ==",
- "dev": true,
"license": "MIT",
"dependencies": {
"call-bind-apply-helpers": "^1.0.2",
@@ -3487,7 +3569,6 @@
"version": "1.0.1",
"resolved": "https://registry.npmjs.org/get-proto/-/get-proto-1.0.1.tgz",
"integrity": "sha512-sTSfBjoXBp89JvIKIefqw7U2CCebsc74kiY6awiGogKtoSGbgjYE/G/+l9sF3MWFPNc9IcoOC4ODfKHfxFmp0g==",
- "dev": true,
"license": "MIT",
"dependencies": {
"dunder-proto": "^1.0.1",
@@ -3575,7 +3656,6 @@
"version": "1.2.0",
"resolved": "https://registry.npmjs.org/gopd/-/gopd-1.2.0.tgz",
"integrity": "sha512-ZUKRh6/kUFoAiTAtTYPZJ3hw9wNxx+BIBOijnlG9PnrJsCcSjs1wyyD6vJpaYtgnzDrKYRSqf3OO6Rfa93xsRg==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -3654,7 +3734,6 @@
"version": "1.1.0",
"resolved": "https://registry.npmjs.org/has-symbols/-/has-symbols-1.1.0.tgz",
"integrity": "sha512-1cDNdwJ2Jaohmb3sg4OmKaMBwuC48sYni5HUw2DvsC8LjGTLK9h+eb1X6RyuOHe4hT0ULCW68iomhjUoKUqlPQ==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -3667,7 +3746,6 @@
"version": "1.0.2",
"resolved": "https://registry.npmjs.org/has-tostringtag/-/has-tostringtag-1.0.2.tgz",
"integrity": "sha512-NqADB8VjPFLM2V0VvHUewwwsw0ZWBaIdgo+ieHtK3hasLz4qeCRjYcqfB6AQrBggRKppKF8L52/VqdVsO47Dlw==",
- "dev": true,
"license": "MIT",
"dependencies": {
"has-symbols": "^1.0.3"
@@ -3683,7 +3761,6 @@
"version": "2.0.2",
"resolved": "https://registry.npmjs.org/hasown/-/hasown-2.0.2.tgz",
"integrity": "sha512-0hJU9SCPvmMzIBdZFqNPXWa6dqh7WdH0cII9y+CyS8rG3nL48Bclra9HmKhVVUHyPWNH5Y7xDwAB7bfgSjkUMQ==",
- "dev": true,
"license": "MIT",
"dependencies": {
"function-bind": "^1.1.2"
@@ -4599,7 +4676,6 @@
"version": "1.1.0",
"resolved": "https://registry.npmjs.org/math-intrinsics/-/math-intrinsics-1.1.0.tgz",
"integrity": "sha512-/IXtbwEk5HTPyEwyKX6hGkYXxM9nbj64B+ilVJnC/R6B0pH5G4V3b0pVbL7DBj4tkhBAppbQUlf6F6Xl9LHu1g==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -4629,6 +4705,27 @@
"node": ">=8.6"
}
},
+ "node_modules/mime-db": {
+ "version": "1.52.0",
+ "resolved": "https://registry.npmjs.org/mime-db/-/mime-db-1.52.0.tgz",
+ "integrity": "sha512-sPU4uV7dYlvtWJxwwxHD0PuihVNiE7TyAbQ5SWxDCB9mUYvOgroQOwYQQOKPJ8CIbE+1ETVlOoK1UC2nU3gYvg==",
+ "license": "MIT",
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
+ "node_modules/mime-types": {
+ "version": "2.1.35",
+ "resolved": "https://registry.npmjs.org/mime-types/-/mime-types-2.1.35.tgz",
+ "integrity": "sha512-ZDY+bPm5zTTF+YpCrAU9nK0UgICYPT0QtT1NZWFv4s++TNkcgVaT0g6+4R2uI4MjQjzysHB1zxuWL50hzaeXiw==",
+ "license": "MIT",
+ "dependencies": {
+ "mime-db": "1.52.0"
+ },
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
"node_modules/minimatch": {
"version": "3.1.2",
"resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.1.2.tgz",
@@ -5130,6 +5227,12 @@
"react-is": "^16.13.1"
}
},
+ "node_modules/proxy-from-env": {
+ "version": "1.1.0",
+ "resolved": "https://registry.npmjs.org/proxy-from-env/-/proxy-from-env-1.1.0.tgz",
+ "integrity": "sha512-D+zkORCbA9f1tdWRK0RaCR3GPv50cMxcrz4X8k5LTSUD1Dkw47mKJEZQNunItRTkWwgtaUSo1RVFRIG9ZXiFYg==",
+ "license": "MIT"
+ },
"node_modules/punycode": {
"version": "2.3.1",
"resolved": "https://registry.npmjs.org/punycode/-/punycode-2.3.1.tgz",
@@ -6046,6 +6149,12 @@
"node": ">=14.17"
}
},
+ "node_modules/typescript-event-target": {
+ "version": "1.1.1",
+ "resolved": "https://registry.npmjs.org/typescript-event-target/-/typescript-event-target-1.1.1.tgz",
+ "integrity": "sha512-dFSOFBKV6uwaloBCCUhxlD3Pr/P1a/tJdcmPrTXCHlEFD3faj0mztjcGn6VBAhQ0/Bdy8K3VWrrqwbt/ffsYsg==",
+ "license": "MIT"
+ },
"node_modules/unbox-primitive": {
"version": "1.1.0",
"resolved": "https://registry.npmjs.org/unbox-primitive/-/unbox-primitive-1.1.0.tgz",
@@ -6254,6 +6363,24 @@
"funding": {
"url": "https://github.com/sponsors/sindresorhus"
}
+ },
+ "node_modules/zod": {
+ "version": "3.25.76",
+ "resolved": "https://registry.npmjs.org/zod/-/zod-3.25.76.tgz",
+ "integrity": "sha512-gzUt/qt81nXsFGKIFcC3YnfEAx5NkunCfnDlvuBSSFS02bcXu4Lmea0AFIUwbLWxWPx3d9p8S5QoaujKcNQxcQ==",
+ "license": "MIT",
+ "funding": {
+ "url": "https://github.com/sponsors/colinhacks"
+ }
+ },
+ "node_modules/zod-to-json-schema": {
+ "version": "3.24.6",
+ "resolved": "https://registry.npmjs.org/zod-to-json-schema/-/zod-to-json-schema-3.24.6.tgz",
+ "integrity": "sha512-h/z3PKvcTcTetyjl1fkj79MHNEjm+HpD6NXheWjzOekY7kV+lwDYnHw+ivHkijnCSMz1yJaWBD9vu/Fcmk+vEg==",
+ "license": "ISC",
+ "peerDependencies": {
+ "zod": "^3.24.1"
+ }
}
}
}
diff --git a/package.json b/package.json
index 93dd610..47dd5b1 100644
--- a/package.json
+++ b/package.json
@@ -9,6 +9,7 @@
"lint": "eslint"
},
"dependencies": {
+ "@mendable/firecrawl-js": "^4.3.5",
"@radix-ui/react-progress": "^1.1.7",
"@radix-ui/react-slot": "^1.2.3",
"class-variance-authority": "^0.7.1",
diff --git a/src/app/api/scrape/route.ts b/src/app/api/scrape/route.ts
new file mode 100644
index 0000000..b3dc6d4
--- /dev/null
+++ b/src/app/api/scrape/route.ts
@@ -0,0 +1,59 @@
+import { NextRequest, NextResponse } from 'next/server';
+import Firecrawl from '@mendable/firecrawl-js';
+
+export async function POST(request: NextRequest) {
+ try {
+ const { url } = await request.json();
+
+ if (!url) {
+ return NextResponse.json(
+ { error: 'URL is required' },
+ { status: 400 }
+ );
+ }
+
+ // Initialize Firecrawl with API key from environment
+ const firecrawl = new Firecrawl({
+ apiKey: process.env.FIRECRAWL_API_KEY
+ });
+
+ console.log('Attempting to scrape URL:', url);
+
+ // Scrape the website
+ const result = await firecrawl.scrape(url, {
+ formats: ['markdown', 'html']
+ });
+
+ console.log('Firecrawl result received');
+
+ // Check if we have the expected data structure
+ if (!result || !result.markdown) {
+ console.error('Invalid Firecrawl response:', result);
+ throw new Error('Invalid response from Firecrawl API');
+ }
+
+ // Create a truncated excerpt for display
+ const excerpt = result.markdown
+ ? result.markdown.substring(0, 200) + (result.markdown.length > 200 ? '...' : '')
+ : 'No content available';
+
+ return NextResponse.json({
+ success: true,
+ data: {
+ url: result.metadata?.sourceURL || url,
+ title: result.metadata?.title || 'Untitled',
+ description: result.metadata?.description || '',
+ content: result.markdown || '',
+ excerpt: excerpt,
+ scrapedAt: new Date().toISOString()
+ }
+ });
+
+ } catch (error) {
+ console.error('Scraping error:', error);
+ return NextResponse.json(
+ { error: error instanceof Error ? error.message : 'Failed to scrape website' },
+ { status: 500 }
+ );
+ }
+}
\ No newline at end of file
diff --git a/src/app/page.tsx b/src/app/page.tsx
index a74fcd8..c53248d 100644
--- a/src/app/page.tsx
+++ b/src/app/page.tsx
@@ -22,17 +22,60 @@ export default function Home() {
const [currentTime, setCurrentTime] = useState(0);
const [duration, setDuration] = useState(0);
const [progressInterval, setProgressInterval] = useState
+
+## Contributing
+
+We love contributions! Please read our [contributing guide](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md) before submitting a pull request.
diff --git a/package-lock.json b/package-lock.json
index 623af58..1840cc3 100644
--- a/package-lock.json
+++ b/package-lock.json
@@ -8,6 +8,7 @@
"name": "ai-podcast",
"version": "0.1.0",
"dependencies": {
+ "@mendable/firecrawl-js": "^4.3.5",
"@radix-ui/react-progress": "^1.1.7",
"@radix-ui/react-slot": "^1.2.3",
"class-variance-authority": "^0.7.1",
@@ -761,6 +762,21 @@
"@jridgewell/sourcemap-codec": "^1.4.14"
}
},
+ "node_modules/@mendable/firecrawl-js": {
+ "version": "4.3.5",
+ "resolved": "https://registry.npmjs.org/@mendable/firecrawl-js/-/firecrawl-js-4.3.5.tgz",
+ "integrity": "sha512-6Vd0bEVD0hOS4SXlmrBnOkm86WWqEITHSTXwdnjm6SkTz6ZF6o85gGHUvOYoky4w7AoLctAv8yqrm6aZsy4lfQ==",
+ "license": "MIT",
+ "dependencies": {
+ "axios": "^1.12.2",
+ "typescript-event-target": "^1.1.1",
+ "zod": "^3.23.8",
+ "zod-to-json-schema": "^3.23.0"
+ },
+ "engines": {
+ "node": ">=22.0.0"
+ }
+ },
"node_modules/@napi-rs/wasm-runtime": {
"version": "0.2.12",
"resolved": "https://registry.npmjs.org/@napi-rs/wasm-runtime/-/wasm-runtime-0.2.12.tgz",
@@ -2229,6 +2245,12 @@
"node": ">= 0.4"
}
},
+ "node_modules/asynckit": {
+ "version": "0.4.0",
+ "resolved": "https://registry.npmjs.org/asynckit/-/asynckit-0.4.0.tgz",
+ "integrity": "sha512-Oei9OH4tRh0YqU3GxhX79dM/mwVgvbZJaSNaRk+bshkj0S5cfHcgYakreBjrHwatXKbz+IoIdYLxrKim2MjW0Q==",
+ "license": "MIT"
+ },
"node_modules/available-typed-arrays": {
"version": "1.0.7",
"resolved": "https://registry.npmjs.org/available-typed-arrays/-/available-typed-arrays-1.0.7.tgz",
@@ -2255,6 +2277,17 @@
"node": ">=4"
}
},
+ "node_modules/axios": {
+ "version": "1.12.2",
+ "resolved": "https://registry.npmjs.org/axios/-/axios-1.12.2.tgz",
+ "integrity": "sha512-vMJzPewAlRyOgxV2dU0Cuz2O8zzzx9VYtbJOaBgXFeLc4IV/Eg50n4LowmehOOR61S8ZMpc2K5Sa7g6A4jfkUw==",
+ "license": "MIT",
+ "dependencies": {
+ "follow-redirects": "^1.15.6",
+ "form-data": "^4.0.4",
+ "proxy-from-env": "^1.1.0"
+ }
+ },
"node_modules/axobject-query": {
"version": "4.1.0",
"resolved": "https://registry.npmjs.org/axobject-query/-/axobject-query-4.1.0.tgz",
@@ -2319,7 +2352,6 @@
"version": "1.0.2",
"resolved": "https://registry.npmjs.org/call-bind-apply-helpers/-/call-bind-apply-helpers-1.0.2.tgz",
"integrity": "sha512-Sp1ablJ0ivDkSzjcaJdxEunN5/XvksFJ2sMBFfq6x0ryhQV/2b/KwFe21cMpmHtPOSij8K99/wSfoEuTObmuMQ==",
- "dev": true,
"license": "MIT",
"dependencies": {
"es-errors": "^1.3.0",
@@ -2450,6 +2482,18 @@
"dev": true,
"license": "MIT"
},
+ "node_modules/combined-stream": {
+ "version": "1.0.8",
+ "resolved": "https://registry.npmjs.org/combined-stream/-/combined-stream-1.0.8.tgz",
+ "integrity": "sha512-FQN4MRfuJeHf7cBbBMJFXhKSDq+2kAArBlmRBvcvFE5BB1HZKXtSFASDhdlz9zOYwxh8lDdnvmMOe/+5cdoEdg==",
+ "license": "MIT",
+ "dependencies": {
+ "delayed-stream": "~1.0.0"
+ },
+ "engines": {
+ "node": ">= 0.8"
+ }
+ },
"node_modules/concat-map": {
"version": "0.0.1",
"resolved": "https://registry.npmjs.org/concat-map/-/concat-map-0.0.1.tgz",
@@ -2601,6 +2645,15 @@
"url": "https://github.com/sponsors/ljharb"
}
},
+ "node_modules/delayed-stream": {
+ "version": "1.0.0",
+ "resolved": "https://registry.npmjs.org/delayed-stream/-/delayed-stream-1.0.0.tgz",
+ "integrity": "sha512-ZySD7Nf91aLB0RxL4KGrKHBXl7Eds1DAmEdcoVawXnLD7SDhpNgtuII2aAkg7a7QS41jxPSZ17p4VdGnMHk3MQ==",
+ "license": "MIT",
+ "engines": {
+ "node": ">=0.4.0"
+ }
+ },
"node_modules/detect-libc": {
"version": "2.1.0",
"resolved": "https://registry.npmjs.org/detect-libc/-/detect-libc-2.1.0.tgz",
@@ -2628,7 +2681,6 @@
"version": "1.0.1",
"resolved": "https://registry.npmjs.org/dunder-proto/-/dunder-proto-1.0.1.tgz",
"integrity": "sha512-KIN/nDJBQRcXw0MLVhZE9iQHmG68qAVIBg9CqmUYjmQIhgij9U5MFvrqkUL5FbtyyzZuOeOt0zdeRe4UY7ct+A==",
- "dev": true,
"license": "MIT",
"dependencies": {
"call-bind-apply-helpers": "^1.0.1",
@@ -2733,7 +2785,6 @@
"version": "1.0.1",
"resolved": "https://registry.npmjs.org/es-define-property/-/es-define-property-1.0.1.tgz",
"integrity": "sha512-e3nRfgfUZ4rNGL232gUgX06QNyyez04KdjFrF+LTRoOXmrOgFKDg4BCdsjW8EnT69eqdYGmRpJwiPVYNrCaW3g==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -2743,7 +2794,6 @@
"version": "1.3.0",
"resolved": "https://registry.npmjs.org/es-errors/-/es-errors-1.3.0.tgz",
"integrity": "sha512-Zf5H2Kxt2xjTvbJvP2ZWLEICxA6j+hAmMzIlypy4xcBg1vKVnx89Wy0GbS+kf5cwCVFFzdCFh2XSCFNULS6csw==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -2781,7 +2831,6 @@
"version": "1.1.1",
"resolved": "https://registry.npmjs.org/es-object-atoms/-/es-object-atoms-1.1.1.tgz",
"integrity": "sha512-FGgH2h8zKNim9ljj7dankFPcICIK9Cp5bm+c2gQSYePhpaG5+esrLODihIorn+Pe6FGJzWhXQotPv73jTaldXA==",
- "dev": true,
"license": "MIT",
"dependencies": {
"es-errors": "^1.3.0"
@@ -2794,7 +2843,6 @@
"version": "2.1.0",
"resolved": "https://registry.npmjs.org/es-set-tostringtag/-/es-set-tostringtag-2.1.0.tgz",
"integrity": "sha512-j6vWzfrGVfyXxge+O0x5sh6cvxAog0a/4Rdd2K36zCMV5eJ+/+tOAngRO8cODMNWbVRdVlmGZQL2YS3yR8bIUA==",
- "dev": true,
"license": "MIT",
"dependencies": {
"es-errors": "^1.3.0",
@@ -3401,6 +3449,26 @@
"dev": true,
"license": "ISC"
},
+ "node_modules/follow-redirects": {
+ "version": "1.15.11",
+ "resolved": "https://registry.npmjs.org/follow-redirects/-/follow-redirects-1.15.11.tgz",
+ "integrity": "sha512-deG2P0JfjrTxl50XGCDyfI97ZGVCxIpfKYmfyrQ54n5FO/0gfIES8C/Psl6kWVDolizcaaxZJnTS0QSMxvnsBQ==",
+ "funding": [
+ {
+ "type": "individual",
+ "url": "https://github.com/sponsors/RubenVerborgh"
+ }
+ ],
+ "license": "MIT",
+ "engines": {
+ "node": ">=4.0"
+ },
+ "peerDependenciesMeta": {
+ "debug": {
+ "optional": true
+ }
+ }
+ },
"node_modules/for-each": {
"version": "0.3.5",
"resolved": "https://registry.npmjs.org/for-each/-/for-each-0.3.5.tgz",
@@ -3417,11 +3485,26 @@
"url": "https://github.com/sponsors/ljharb"
}
},
+ "node_modules/form-data": {
+ "version": "4.0.4",
+ "resolved": "https://registry.npmjs.org/form-data/-/form-data-4.0.4.tgz",
+ "integrity": "sha512-KrGhL9Q4zjj0kiUt5OO4Mr/A/jlI2jDYs5eHBpYHPcBEVSiipAvn2Ko2HnPe20rmcuuvMHNdZFp+4IlGTMF0Ow==",
+ "license": "MIT",
+ "dependencies": {
+ "asynckit": "^0.4.0",
+ "combined-stream": "^1.0.8",
+ "es-set-tostringtag": "^2.1.0",
+ "hasown": "^2.0.2",
+ "mime-types": "^2.1.12"
+ },
+ "engines": {
+ "node": ">= 6"
+ }
+ },
"node_modules/function-bind": {
"version": "1.1.2",
"resolved": "https://registry.npmjs.org/function-bind/-/function-bind-1.1.2.tgz",
"integrity": "sha512-7XHNxH7qX9xG5mIwxkhumTox/MIRNcOgDrxWsMt2pAr23WHp6MrRlN7FBSFpCpr+oVO0F744iUgR82nJMfG2SA==",
- "dev": true,
"license": "MIT",
"funding": {
"url": "https://github.com/sponsors/ljharb"
@@ -3462,7 +3545,6 @@
"version": "1.3.0",
"resolved": "https://registry.npmjs.org/get-intrinsic/-/get-intrinsic-1.3.0.tgz",
"integrity": "sha512-9fSjSaos/fRIVIp+xSJlE6lfwhES7LNtKaCBIamHsjr2na1BiABJPo0mOjjz8GJDURarmCPGqaiVg5mfjb98CQ==",
- "dev": true,
"license": "MIT",
"dependencies": {
"call-bind-apply-helpers": "^1.0.2",
@@ -3487,7 +3569,6 @@
"version": "1.0.1",
"resolved": "https://registry.npmjs.org/get-proto/-/get-proto-1.0.1.tgz",
"integrity": "sha512-sTSfBjoXBp89JvIKIefqw7U2CCebsc74kiY6awiGogKtoSGbgjYE/G/+l9sF3MWFPNc9IcoOC4ODfKHfxFmp0g==",
- "dev": true,
"license": "MIT",
"dependencies": {
"dunder-proto": "^1.0.1",
@@ -3575,7 +3656,6 @@
"version": "1.2.0",
"resolved": "https://registry.npmjs.org/gopd/-/gopd-1.2.0.tgz",
"integrity": "sha512-ZUKRh6/kUFoAiTAtTYPZJ3hw9wNxx+BIBOijnlG9PnrJsCcSjs1wyyD6vJpaYtgnzDrKYRSqf3OO6Rfa93xsRg==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -3654,7 +3734,6 @@
"version": "1.1.0",
"resolved": "https://registry.npmjs.org/has-symbols/-/has-symbols-1.1.0.tgz",
"integrity": "sha512-1cDNdwJ2Jaohmb3sg4OmKaMBwuC48sYni5HUw2DvsC8LjGTLK9h+eb1X6RyuOHe4hT0ULCW68iomhjUoKUqlPQ==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -3667,7 +3746,6 @@
"version": "1.0.2",
"resolved": "https://registry.npmjs.org/has-tostringtag/-/has-tostringtag-1.0.2.tgz",
"integrity": "sha512-NqADB8VjPFLM2V0VvHUewwwsw0ZWBaIdgo+ieHtK3hasLz4qeCRjYcqfB6AQrBggRKppKF8L52/VqdVsO47Dlw==",
- "dev": true,
"license": "MIT",
"dependencies": {
"has-symbols": "^1.0.3"
@@ -3683,7 +3761,6 @@
"version": "2.0.2",
"resolved": "https://registry.npmjs.org/hasown/-/hasown-2.0.2.tgz",
"integrity": "sha512-0hJU9SCPvmMzIBdZFqNPXWa6dqh7WdH0cII9y+CyS8rG3nL48Bclra9HmKhVVUHyPWNH5Y7xDwAB7bfgSjkUMQ==",
- "dev": true,
"license": "MIT",
"dependencies": {
"function-bind": "^1.1.2"
@@ -4599,7 +4676,6 @@
"version": "1.1.0",
"resolved": "https://registry.npmjs.org/math-intrinsics/-/math-intrinsics-1.1.0.tgz",
"integrity": "sha512-/IXtbwEk5HTPyEwyKX6hGkYXxM9nbj64B+ilVJnC/R6B0pH5G4V3b0pVbL7DBj4tkhBAppbQUlf6F6Xl9LHu1g==",
- "dev": true,
"license": "MIT",
"engines": {
"node": ">= 0.4"
@@ -4629,6 +4705,27 @@
"node": ">=8.6"
}
},
+ "node_modules/mime-db": {
+ "version": "1.52.0",
+ "resolved": "https://registry.npmjs.org/mime-db/-/mime-db-1.52.0.tgz",
+ "integrity": "sha512-sPU4uV7dYlvtWJxwwxHD0PuihVNiE7TyAbQ5SWxDCB9mUYvOgroQOwYQQOKPJ8CIbE+1ETVlOoK1UC2nU3gYvg==",
+ "license": "MIT",
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
+ "node_modules/mime-types": {
+ "version": "2.1.35",
+ "resolved": "https://registry.npmjs.org/mime-types/-/mime-types-2.1.35.tgz",
+ "integrity": "sha512-ZDY+bPm5zTTF+YpCrAU9nK0UgICYPT0QtT1NZWFv4s++TNkcgVaT0g6+4R2uI4MjQjzysHB1zxuWL50hzaeXiw==",
+ "license": "MIT",
+ "dependencies": {
+ "mime-db": "1.52.0"
+ },
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
"node_modules/minimatch": {
"version": "3.1.2",
"resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.1.2.tgz",
@@ -5130,6 +5227,12 @@
"react-is": "^16.13.1"
}
},
+ "node_modules/proxy-from-env": {
+ "version": "1.1.0",
+ "resolved": "https://registry.npmjs.org/proxy-from-env/-/proxy-from-env-1.1.0.tgz",
+ "integrity": "sha512-D+zkORCbA9f1tdWRK0RaCR3GPv50cMxcrz4X8k5LTSUD1Dkw47mKJEZQNunItRTkWwgtaUSo1RVFRIG9ZXiFYg==",
+ "license": "MIT"
+ },
"node_modules/punycode": {
"version": "2.3.1",
"resolved": "https://registry.npmjs.org/punycode/-/punycode-2.3.1.tgz",
@@ -6046,6 +6149,12 @@
"node": ">=14.17"
}
},
+ "node_modules/typescript-event-target": {
+ "version": "1.1.1",
+ "resolved": "https://registry.npmjs.org/typescript-event-target/-/typescript-event-target-1.1.1.tgz",
+ "integrity": "sha512-dFSOFBKV6uwaloBCCUhxlD3Pr/P1a/tJdcmPrTXCHlEFD3faj0mztjcGn6VBAhQ0/Bdy8K3VWrrqwbt/ffsYsg==",
+ "license": "MIT"
+ },
"node_modules/unbox-primitive": {
"version": "1.1.0",
"resolved": "https://registry.npmjs.org/unbox-primitive/-/unbox-primitive-1.1.0.tgz",
@@ -6254,6 +6363,24 @@
"funding": {
"url": "https://github.com/sponsors/sindresorhus"
}
+ },
+ "node_modules/zod": {
+ "version": "3.25.76",
+ "resolved": "https://registry.npmjs.org/zod/-/zod-3.25.76.tgz",
+ "integrity": "sha512-gzUt/qt81nXsFGKIFcC3YnfEAx5NkunCfnDlvuBSSFS02bcXu4Lmea0AFIUwbLWxWPx3d9p8S5QoaujKcNQxcQ==",
+ "license": "MIT",
+ "funding": {
+ "url": "https://github.com/sponsors/colinhacks"
+ }
+ },
+ "node_modules/zod-to-json-schema": {
+ "version": "3.24.6",
+ "resolved": "https://registry.npmjs.org/zod-to-json-schema/-/zod-to-json-schema-3.24.6.tgz",
+ "integrity": "sha512-h/z3PKvcTcTetyjl1fkj79MHNEjm+HpD6NXheWjzOekY7kV+lwDYnHw+ivHkijnCSMz1yJaWBD9vu/Fcmk+vEg==",
+ "license": "ISC",
+ "peerDependencies": {
+ "zod": "^3.24.1"
+ }
}
}
}
diff --git a/package.json b/package.json
index 93dd610..47dd5b1 100644
--- a/package.json
+++ b/package.json
@@ -9,6 +9,7 @@
"lint": "eslint"
},
"dependencies": {
+ "@mendable/firecrawl-js": "^4.3.5",
"@radix-ui/react-progress": "^1.1.7",
"@radix-ui/react-slot": "^1.2.3",
"class-variance-authority": "^0.7.1",
diff --git a/src/app/api/scrape/route.ts b/src/app/api/scrape/route.ts
new file mode 100644
index 0000000..b3dc6d4
--- /dev/null
+++ b/src/app/api/scrape/route.ts
@@ -0,0 +1,59 @@
+import { NextRequest, NextResponse } from 'next/server';
+import Firecrawl from '@mendable/firecrawl-js';
+
+export async function POST(request: NextRequest) {
+ try {
+ const { url } = await request.json();
+
+ if (!url) {
+ return NextResponse.json(
+ { error: 'URL is required' },
+ { status: 400 }
+ );
+ }
+
+ // Initialize Firecrawl with API key from environment
+ const firecrawl = new Firecrawl({
+ apiKey: process.env.FIRECRAWL_API_KEY
+ });
+
+ console.log('Attempting to scrape URL:', url);
+
+ // Scrape the website
+ const result = await firecrawl.scrape(url, {
+ formats: ['markdown', 'html']
+ });
+
+ console.log('Firecrawl result received');
+
+ // Check if we have the expected data structure
+ if (!result || !result.markdown) {
+ console.error('Invalid Firecrawl response:', result);
+ throw new Error('Invalid response from Firecrawl API');
+ }
+
+ // Create a truncated excerpt for display
+ const excerpt = result.markdown
+ ? result.markdown.substring(0, 200) + (result.markdown.length > 200 ? '...' : '')
+ : 'No content available';
+
+ return NextResponse.json({
+ success: true,
+ data: {
+ url: result.metadata?.sourceURL || url,
+ title: result.metadata?.title || 'Untitled',
+ description: result.metadata?.description || '',
+ content: result.markdown || '',
+ excerpt: excerpt,
+ scrapedAt: new Date().toISOString()
+ }
+ });
+
+ } catch (error) {
+ console.error('Scraping error:', error);
+ return NextResponse.json(
+ { error: error instanceof Error ? error.message : 'Failed to scrape website' },
+ { status: 500 }
+ );
+ }
+}
\ No newline at end of file
diff --git a/src/app/page.tsx b/src/app/page.tsx
index a74fcd8..c53248d 100644
--- a/src/app/page.tsx
+++ b/src/app/page.tsx
@@ -22,17 +22,60 @@ export default function Home() {
const [currentTime, setCurrentTime] = useState(0);
const [duration, setDuration] = useState(0);
const [progressInterval, setProgressInterval] = useState+ {source.excerpt} +
++ {source.url} +
+- Podcast generated successfully! Listen to the conversation below. + Website scraped successfully! Content is ready for podcast generation.